Learning to Merge Tokens for Communication-Efficient Collaborative Occupancy Prediction
Token-based collaborative semantic occupancy prediction with spatio-temporal memory, receiver-driven communication, and content-aware token merging
Overview
This project studies communication-efficient collaborative semantic occupancy prediction for connected autonomous vehicles. Semantic occupancy prediction aims to reconstruct a dense 3D voxel representation of the surrounding scene, while collaborative perception allows the ego vehicle to leverage complementary observations from neighboring agents.
The key challenge is that collaborative occupancy prediction requires exchanging high-dimensional scene representations, which can introduce heavy communication overhead. This project addresses this problem by representing the scene with compact BEV tokens and learning how to selectively request, merge, transmit, and fuse task-relevant tokens under limited bandwidth.
In this work, communication is treated as an active, receiver-conditioned process rather than passive broadcasting. The ego vehicle identifies uncertain or under-supported regions, neighboring agents score their tokens according to the ego request, and redundant sender-side tokens are merged before transmission.
The work has been submitted to NeurIPS 2026.
Framework
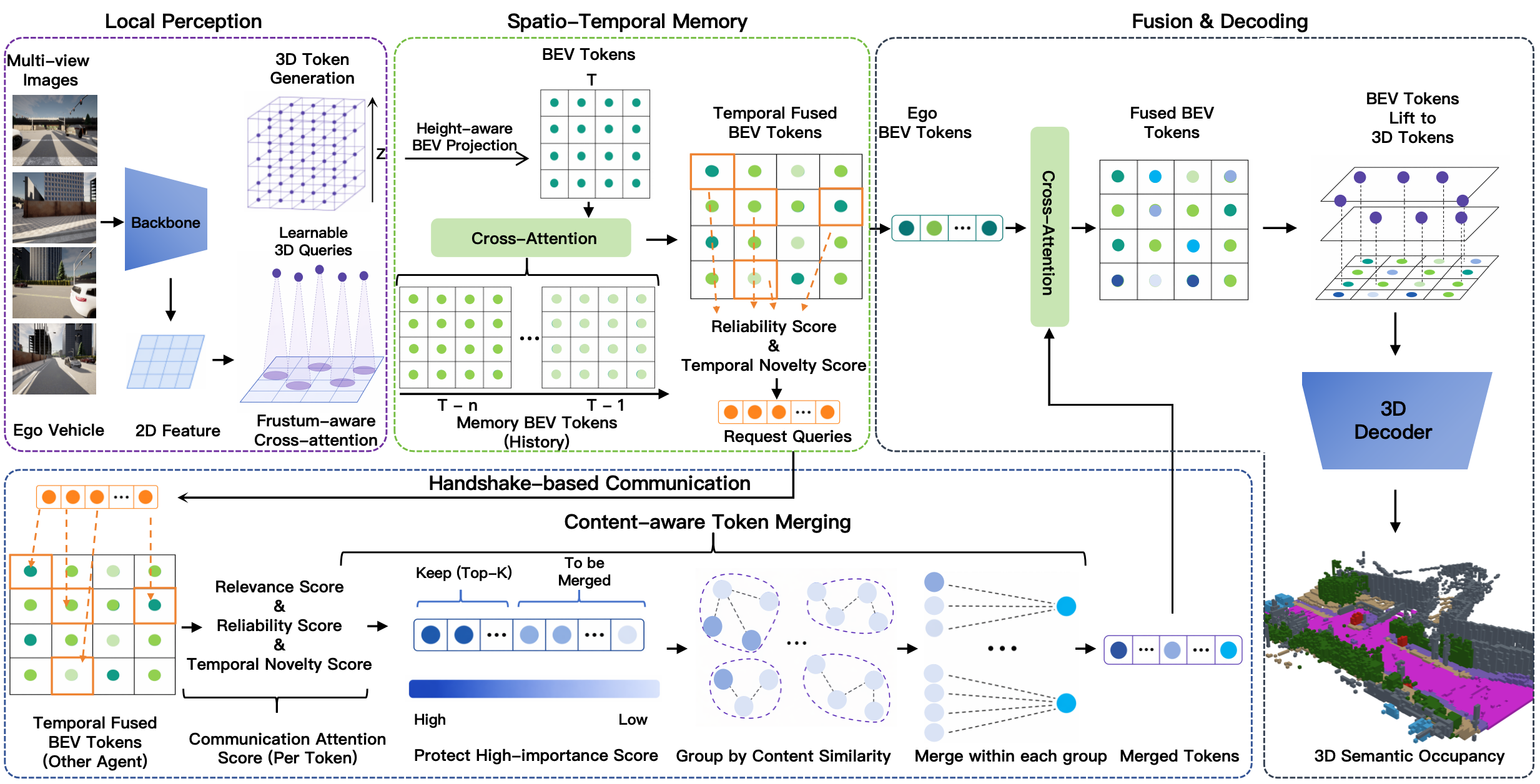
The framework uses BEV tokens as unified carriers for local perception, temporal memory, inter-agent communication, and collaborative fusion. Multi-view images are lifted into 3D tokens and projected into BEV tokens. A spatio-temporal memory aggregates historical BEV tokens, the ego vehicle generates receiver-side requests, neighboring agents compute communication attention scores, and content-aware token merging compresses redundant tokens before transmission.
Motivation
Single-agent perception is often limited by occlusions and restricted fields of view. Collaborative perception can recover missing or weakly observed regions by using information from nearby agents, but dense feature sharing is expensive and redundant.
This project asks:
- How can agents communicate compact 3D scene representations instead of dense feature maps?
- How can the ego agent request only task-relevant information from its neighbors?
- How can redundant sender-side tokens be compressed without losing useful occupancy evidence?
- How can we improve the accuracy–communication trade-off for collaborative semantic occupancy prediction?
The motivation is closely related to real deployment. Connected autonomous vehicles cannot assume unlimited bandwidth, and multi-agent perception systems must decide what information is worth transmitting. A useful collaborative perception model should therefore be accurate, bandwidth-aware, and robust to partial observations.
Problem Formulation
Given an ego agent (i) and a set of neighboring agents (\mathcal{N}_i), the goal is to predict the semantic occupancy volume:
[ \hat{O}i = f\theta(X_i, {M_{j \rightarrow i}}_{j \in \mathcal{N}_i}) ]
where:
- (X_i) is the ego observation;
- (M_{j \rightarrow i}) is the transmitted message from neighbor (j) to ego (i);
- (\hat{O}_i) is the predicted semantic occupancy grid.
The communication budget constrains the messages:
[ \sum_{j \in \mathcal{N}i} \mathrm{Cost}(M{j \rightarrow i}) \leq B ]
The project optimizes for high occupancy accuracy under this communication budget. In practice, this means transmitting a compact set of tokens rather than dense intermediate feature maps.
Main Contributions
The project contributes a token-based collaborative occupancy framework with four main components:
- Tokenized 3D/BEV scene representation for compact occupancy-oriented communication.
- Spatio-temporal memory to reuse historical scene information and reduce frame-level uncertainty.
- Receiver-driven handshake communication to request information from uncertain or weakly supported ego regions.
- Content-aware token merging to compress redundant sender tokens while preserving request-relevant evidence.
Method
The proposed framework uses BEV tokens as unified carriers for local perception, temporal memory, inter-agent communication, and collaborative fusion.
Tokenized 3D Scene Representation
Each agent extracts multi-view image features, lifts them into sparse 3D tokens with learnable queries, and projects them into BEV tokens through height-aware projection. These BEV tokens provide a compact representation for both perception and communication.
Compared with dense feature maps, BEV tokens make communication more flexible. Tokens can be ranked, selected, merged, stored in memory, or fused through attention. This makes them suitable for bandwidth-constrained collaborative perception.
Spatio-Temporal Memory
Each agent maintains a short-term spatio-temporal memory over historical BEV tokens. Historical tokens are motion-aligned to the current frame and fused with current BEV tokens using cross-attention, producing temporally enhanced scene representations.
The memory module is especially useful for regions that are temporarily occluded or poorly observed in the current frame. Instead of relying only on the current image, the model can reuse aligned historical evidence.
Handshake-Based Communication
Instead of receiving dense messages from all neighbors, the ego vehicle generates request queries from unreliable and temporally under-supported regions. Neighboring agents then compute receiver-conditioned communication attention scores to identify which tokens are most useful for the ego vehicle.
This handshake mechanism changes the communication pattern from:
sender broadcasts what it has
to:
receiver requests what it needs
This is important because the ego vehicle is the one that knows which regions are uncertain in its own occupancy prediction.
Content-Aware Token Merging
Each sender preserves high-importance request-relevant tokens and merges redundant low-priority tokens into compact representatives. The merging process combines feature similarity and spatial proximity, followed by attention-weighted averaging. This keeps useful complementary information while reducing redundant communication.
The merging operation can be viewed as compressing a large token set (\mathcal{T}) into a smaller message set (\mathcal{M}):
[ \mathcal{T} \rightarrow \mathcal{M}, \quad |\mathcal{M}| \ll |\mathcal{T}| ]
The goal is to keep tokens that improve occupancy prediction while merging tokens that carry similar or redundant information.
System Pipeline
The overall pipeline is:
Multi-view images → 3D token lifting → BEV token projection → spatio-temporal memory → receiver-driven request generation → sender-side token scoring → content-aware token merging → collaborative fusion → 3D occupancy decoding
In this design, tokens act as the common representation for scene encoding, temporal memory, communication, and fusion.
Experimental Setup
Experiments are conducted on Semantic-OPV2V, a collaborative semantic occupancy prediction benchmark built on OPV2V. The evaluation follows the official protocol with synchronized multi-view RGB images and collaborative perception among connected vehicles.
Main settings:
| Setting | Value |
|---|---|
| Dataset | Semantic-OPV2V |
| Occupancy grid | 100 × 100 × 8 |
| Spatial range | 40 m × 40 m × 3.2 m |
| Cameras per agent | 4 RGB views |
| BEV tokens | 100 × 100 |
| Learnable 3D queries | 4320 |
| STM length | 3 frames |
| Max neighboring senders | 6 |
| Transmitted response dimension | 128 |
| Default transmitted tokens / sender | 1000 |
Communication cost is reported as the response feature payload in MB per receiver per frame, aggregated over all neighboring senders.
Main Results
The proposed method achieves the best collaborative occupancy prediction performance among the compared methods while using substantially lower communication cost.
| Method | mIoU ↑ | Communication Cost ↓ |
|---|---|---|
| CoHFF | 34.16 | 4.69 MB |
| VOGS-CP | 37.44 | 6.42 MB |
| Ours | 42.85 | 1.48 MB |
Compared with dense intermediate feature sharing, the token-based communication design provides a stronger accuracy–communication trade-off. The method reaches 42.85% mIoU under full collaboration with only 1.48 MB feature payload per receiver per frame.
This result is important because the method does not simply reduce communication at the cost of accuracy. It improves mIoU while using a much smaller message payload, suggesting that task-aware token selection and merging can remove redundant communication and strengthen useful complementary evidence.
Class-Wise Semantic Occupancy Results
| Metric / Class | CoHFF | VOGS-CP | Ours |
|---|---|---|---|
| IoU ↑ | 50.46 | 72.87 | 74.08 |
| mIoU ↑ | 34.16 | 37.44 | 42.85 |
| Building | 25.72 | 9.61 | 20.73 |
| Fence | 27.83 | 29.20 | 36.61 |
| Terrain | 48.30 | 74.51 | 79.83 |
| Pole | 42.74 | 12.19 | 25.47 |
| Road | 61.77 | 83.05 | 82.24 |
| Sidewalk | 39.62 | 78.22 | 72.45 |
| Vegetation | 20.59 | 20.43 | 26.18 |
| Vehicles | 63.28 | 60.49 | 69.73 |
| Wall | 58.27 | 36.45 | 51.10 |
| Guard rail | 1.94 | 32.50 | 27.32 |
| Traffic signs | 16.33 | 8.26 | 18.03 |
| Bridge | 3.53 | 4.35 | 4.51 |
The largest gains appear in classes that benefit from complementary viewpoints, such as fences, terrain, vegetation, vehicles, traffic signs, and bridges.
Ablation Studies
Representation Capacity and Temporal Modeling
Increasing 3D query density improves spatial representation capacity, while spatio-temporal memory improves robustness by aggregating historical observations.
| 3D Query Density | #Queries | STM Frames | mIoU ↑ |
|---|---|---|---|
| 1× | 1440 | 3 | 36.62 |
| 2× | 2880 | 3 | 38.06 |
| 3× | 4320 | 3 | 42.85 |
| 3× | 4320 | 0 | 39.72 |
| 3× | 4320 | 1 | 41.47 |
| 3× | 4320 | 2 | 42.63 |
| 3× | 4320 | 3 | 42.85 |
Communication Compression
Content-aware token merging reduces communication cost while maintaining strong perception accuracy.
| Setting | #Tokens / Sender | Communication Cost ↓ | mIoU ↑ |
|---|---|---|---|
| Dense communication | 10000 | 14.82 MB | 42.38 |
| Request-guided, no merge | 10000 | 14.82 MB | 42.65 |
| CTM, 50% tokens | 5000 | 7.41 MB | 43.47 |
| CTM, 30% tokens | 3000 | 4.44 MB | 42.91 |
| CTM, 10% tokens | 1000 | 1.48 MB | 42.85 |
The 10% token setting reduces the feature payload from 14.82 MB to 1.48 MB while maintaining competitive mIoU. The 50% setting achieves the highest mIoU, suggesting that moderate token merging can also remove redundant or noisy neighboring information.
Discussion
The experiments suggest several broader lessons:
- Not all collaborative features are equally useful. Many transmitted features are redundant or weakly relevant to the receiver.
- Receiver-side uncertainty is a strong signal for deciding what should be communicated.
- Temporal memory and communication are complementary. Memory stabilizes local perception, while communication fills in missing regions from other viewpoints.
- Token merging can act as both compression and denoising when redundant neighboring information is merged carefully.
These observations motivate my broader research interest in communication-efficient multi-agent perception and token-based 3D scene representations.
Qualitative Results
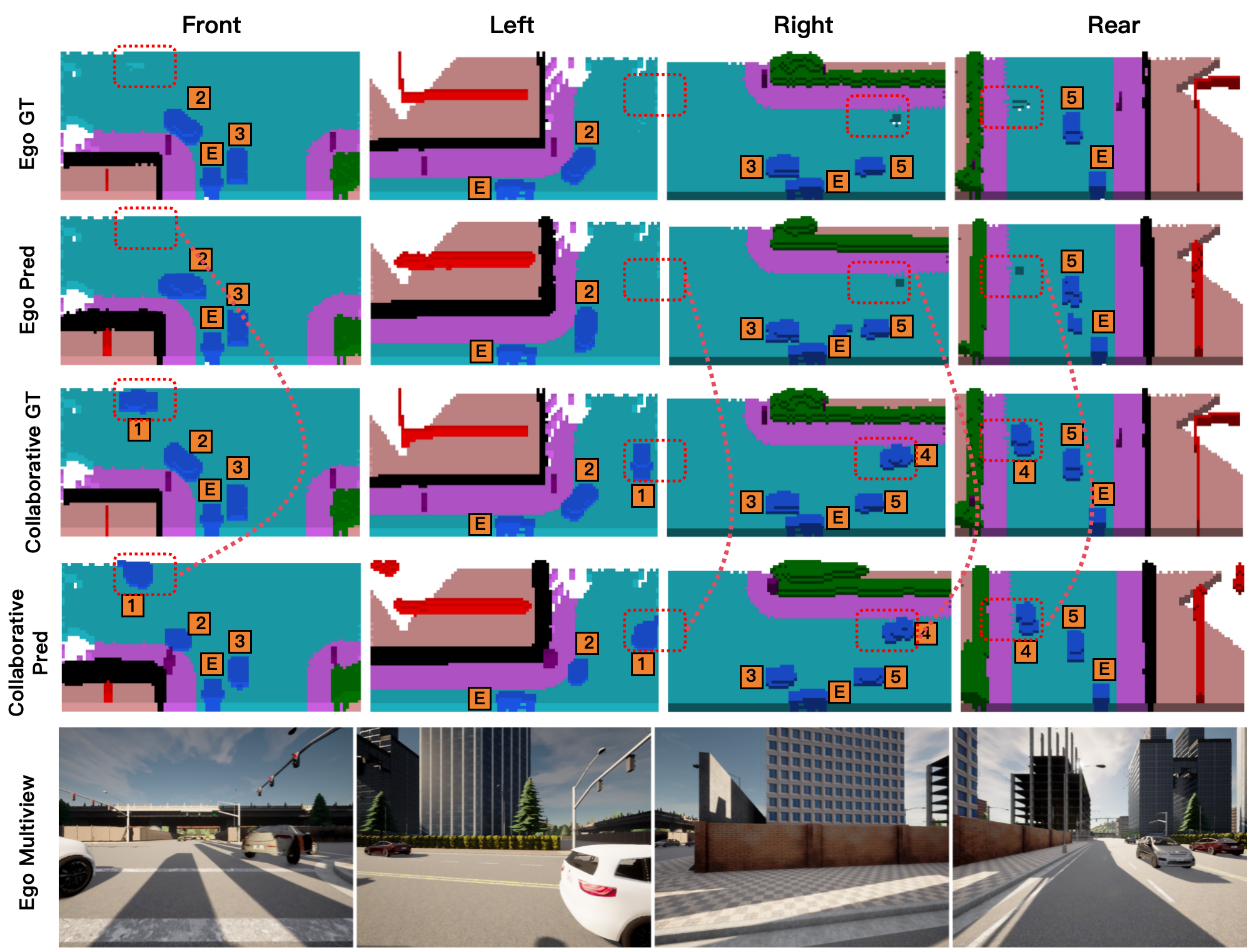
The qualitative results show that collaboration produces more complete semantic occupancy predictions than ego-only perception, especially for vehicles and scene regions outside the ego vehicle’s reliable field of view. The recovered regions demonstrate how compact token communication can complement local perception while keeping the transmitted payload small.
Key Takeaways
- Tokenized BEV representations provide a compact carrier for collaborative occupancy prediction.
- Spatio-temporal memory improves scene representation by aggregating historical BEV tokens.
- Receiver-driven communication helps agents exchange task-relevant information instead of broadcasting dense features.
- Content-aware token merging compresses redundant sender-side tokens while preserving high-importance information.
- The framework achieves a favorable accuracy–communication trade-off on Semantic-OPV2V.
- The project strengthens my research direction around collaborative 3D perception, efficient token communication, and occupancy-based scene understanding.
Status
Submitted to NeurIPS 2026.
More details will be released after the review process.