协同 4D 占用世界模型
结合多智能体观测、运动感知 token 记忆和未来场景预测的占用世界模型研究。
项目概述
本项目探索如何利用 协同感知 支持自动驾驶和具身智能中的 occupancy-based world modeling。
与只重建当前三维场景不同,本项目关注动态环境中的占用状态如何随时间演化。系统希望将 多智能体观测、motion-aware token memory 和 未来占用预测 结合成统一的 4D 世界模型框架。
核心想法是:
协同感知不应该只帮助智能体看清当前世界,还应该帮助智能体预测三维世界将如何变化。
该工作目前是面向 CVPR 2027 准备中的 manuscript。
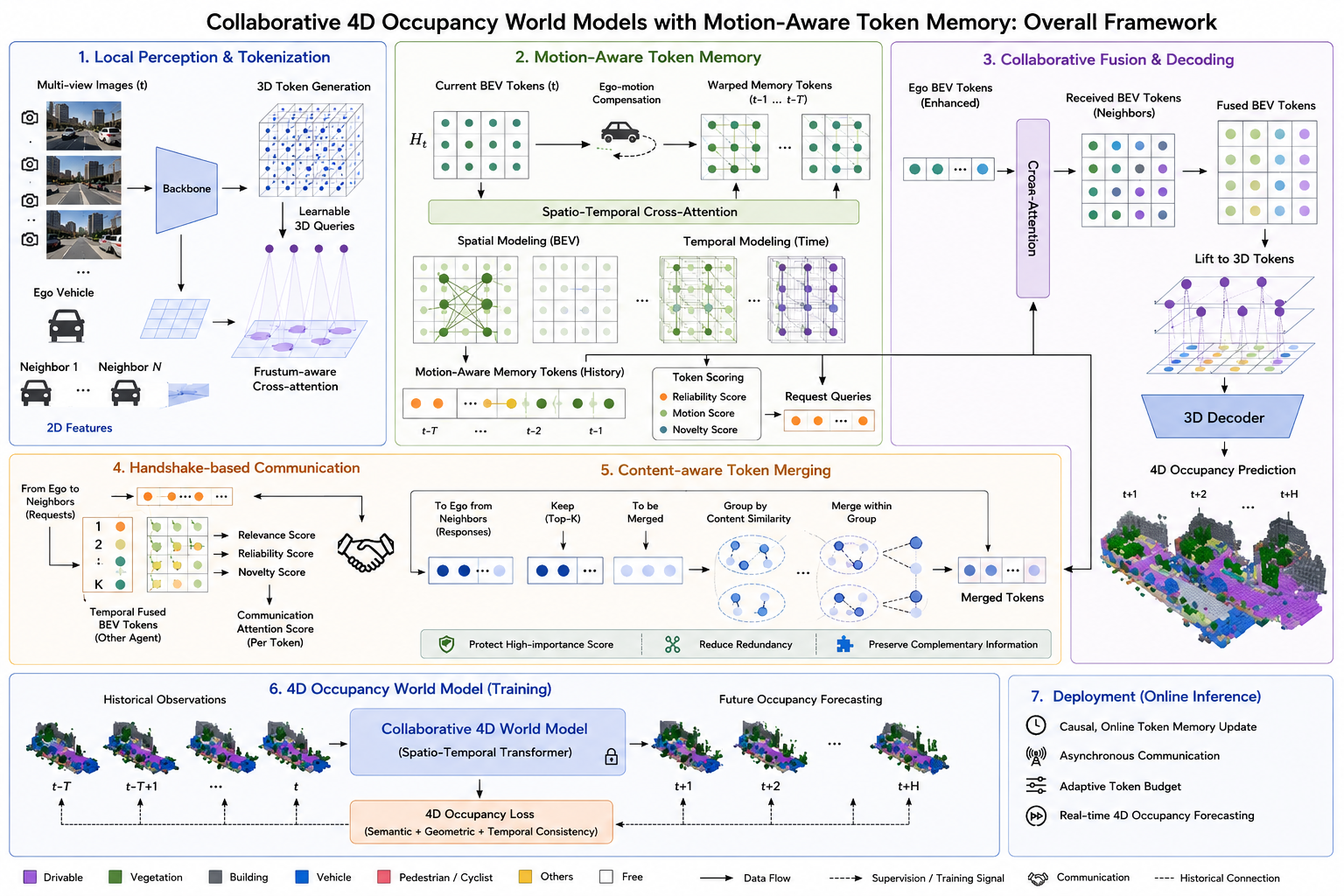
该框架将协同占用预测从当前帧三维重建扩展到面向未来的 4D occupancy world modeling。多视角观测首先被转换成 tokenized 3D/BEV representations,然后维护在 motion-aware token memory 中。协同融合模块整合邻近智能体的互补信息,world-modeling 模块进一步预测未来多个时间步的 occupancy states。
项目动机
大多数语义占用预测方法关注当前三维场景重建。但自动智能体需要的不只是静态场景理解,还需要推理周围物体、free space 和遮挡区域在未来短时间内如何变化。
这对规划和控制很重要。车辆不仅要知道行人现在在哪里,还要估计行人和周围车辆接下来可能移动到哪里。同样,当前可见的 free space 可能在未来被占据,遮挡区域中也可能存在动态物体。
协同感知为这个目标提供了自然基础。不同智能体从互补视角观察环境,可以帮助恢复遮挡区域或不确定区域,并为未来预测提供更丰富的时间证据。
本项目关注:
- 如何将协同三维占用预测扩展到 4D occupancy world modeling?
- 如何维护既包含场景结构又包含运动动态的紧凑 memory tokens?
- 多智能体观测如何改善遮挡和不确定区域的未来预测?
- token-based representation 如何支持可扩展 4D 场景理解?
- predictive occupancy representation 如何服务下游规划?
研究目标
项目目标是将协同三维占用预测进一步表述为 4D 占用世界建模。
给定多个智能体的历史和当前观测,系统不仅预测当前语义占用网格,也预测未来多个时间步的占用状态演化:
[ \hat{O}{t:t+K} = f\theta(X_{1:t}^{1:N}) ]
其中:
- (X_{1:t}^{1:N}) 表示来自 (N) 个智能体的历史观测;
- (\hat{O}_{t:t+K}) 表示当前和未来 occupancy states;
- (K) 是预测时间跨度。
这个方向连接了四类问题:
- 感知:重建当前三维语义场景;
- 时间推理:建模场景如何随时间变化;
- 世界建模:预测未来 occupancy states;
- 规划支持:为自动决策提供预测性空间表示。
核心思想
- 将协同三维占用预测扩展为面向未来的 4D 占用建模。
- 使用运动感知 token 记忆表示历史场景结构和动态变化。
- 利用多智能体互补观测改善遮挡区域和不确定区域的未来预测。
- 探索 token 表示在长时序、可扩展三维世界建模中的作用。
1. 协同 4D 占用建模
项目将 collaborative occupancy prediction 从静态 3D 场景理解扩展到面向未来的 4D 场景建模。多智能体观测提供互补的空间和时间证据。
与把协同看成单帧 feature fusion 不同,该框架把协同视为改善当前和未来场景 belief 的方式。
2. Motion-Aware Token Memory
系统设计 motion-aware token memory,用紧凑 occupancy tokens 捕捉时间动态。相比存储 dense historical features,memory 维护结构化 token,用来表示场景内容和运动变化。
该 memory 预期支持:
- ego-motion compensation;
- historical token alignment;
- dynamic-object motion cues;
- temporal uncertainty tracking;
- compact long-range scene context。
3. 未来占用预测
项目把 future occupancy forecasting 作为连接感知、时间推理和世界模型的桥梁。模型预测 occupied、free 和 semantic regions 如何在未来帧中演化。
对于未来时间步 (t+k),模型预测结构化 occupancy field:
[ \hat{O}_{t+k} \in \mathbb{R}^{X \times Y \times Z \times C} ]
其中 (C) 表示语义占用类别。
4. Token-Based 4D Scene Representation
Token 表示被用于可扩展 4D 场景理解。Token 可以作为多智能体观测、时间记忆和未来预测的紧凑载体,适合长时序和通信感知的世界建模。
Token 表示也天然兼容选择性通信:智能体可以只共享预计能改善未来预测的 memory tokens 或 scene tokens。
5. 不确定性与遮挡推理
未来预测在不确定、遮挡或动态变化区域尤其重要。因此框架考虑 uncertainty-aware fusion and forecasting,使世界模型能集中处理协同和记忆最有价值的区域。
系统概念
计划中的系统流程为:
多智能体观测 -> tokenized 3D scene representation -> motion-aware token memory -> collaborative temporal fusion -> future occupancy forecasting -> 4D occupancy world model
该流程可以理解为三个阶段:
- Encode:将多视角观测转换为紧凑 3D/BEV tokens。
- Remember and collaborate:对齐历史 tokens,并融合邻近智能体的互补信息。
- Forecast:在预测时间跨度内解码当前和未来 occupancy fields。
预期贡献
- 将协同三维占用预测表述为 4D occupancy world modeling。
- 设计 motion-aware token memory 捕捉紧凑 occupancy representation 中的时间动态。
- 利用多智能体观测改善遮挡、不确定和动态区域的未来预测。
- 将 future occupancy forecasting 作为连接感知、时间推理和世界模型的桥梁。
- 探索 token-based representation 在可扩展 4D 场景理解中的作用。
- 研究通信约束下 predictive occupancy modeling 的准确率和效率权衡。
评价计划
项目预计评估:
- 当前帧语义占用质量;
- 未来占用预测准确率;
- 遮挡和动态区域表现;
- 协同观测相比 ego-only prediction 的收益;
- motion-aware token memory 的作用;
- 通信和记忆效率。
可能使用的指标包括 IoU、mIoU、future mIoU、动态物体占用质量,以及通信受限条件下的通信成本。
研究意义
该方向试图让感知系统从当前帧占用预测走向预测性三维场景理解。通过建模未来占用演化,系统可以为需要理解动态环境的自动智能体提供更丰富的表示。
长期目标是构建高效、可靠的感知系统,使其不仅理解当前场景,也能预测周围三维世界如何随时间变化。
该方向连接了我对 协同感知、语义占用预测、token memory 和 world models 的研究兴趣。
状态
手稿准备中,计划面向 CVPR 2027。