面向协同占用预测的通信高效 token 合并
基于 BEV token、时空记忆、接收端请求和内容感知 token 合并的协同语义占用预测方法。
项目概述
本项目研究面向 connected autonomous vehicles 的 通信高效协同语义占用预测。语义占用预测希望重建周围环境的密集三维体素语义结构,而协同感知允许 ego vehicle 利用邻近智能体的互补观测,从而缓解遮挡、视野受限和局部感知不确定性。
核心挑战是:协同占用预测通常需要交换高维场景表示,通信开销很大。本项目通过紧凑的 BEV tokens 表示场景,并学习如何在有限带宽下选择、请求、合并、传输和融合 task-relevant tokens。
在该工作中,通信不是被动 broadcast,而是一个主动的 receiver-conditioned 过程。ego 车辆识别不确定或时间支持不足的区域,邻近智能体根据 ego request 对自身 tokens 进行评分,并在发送前合并冗余 tokens。
该工作已投稿 NeurIPS 2026。
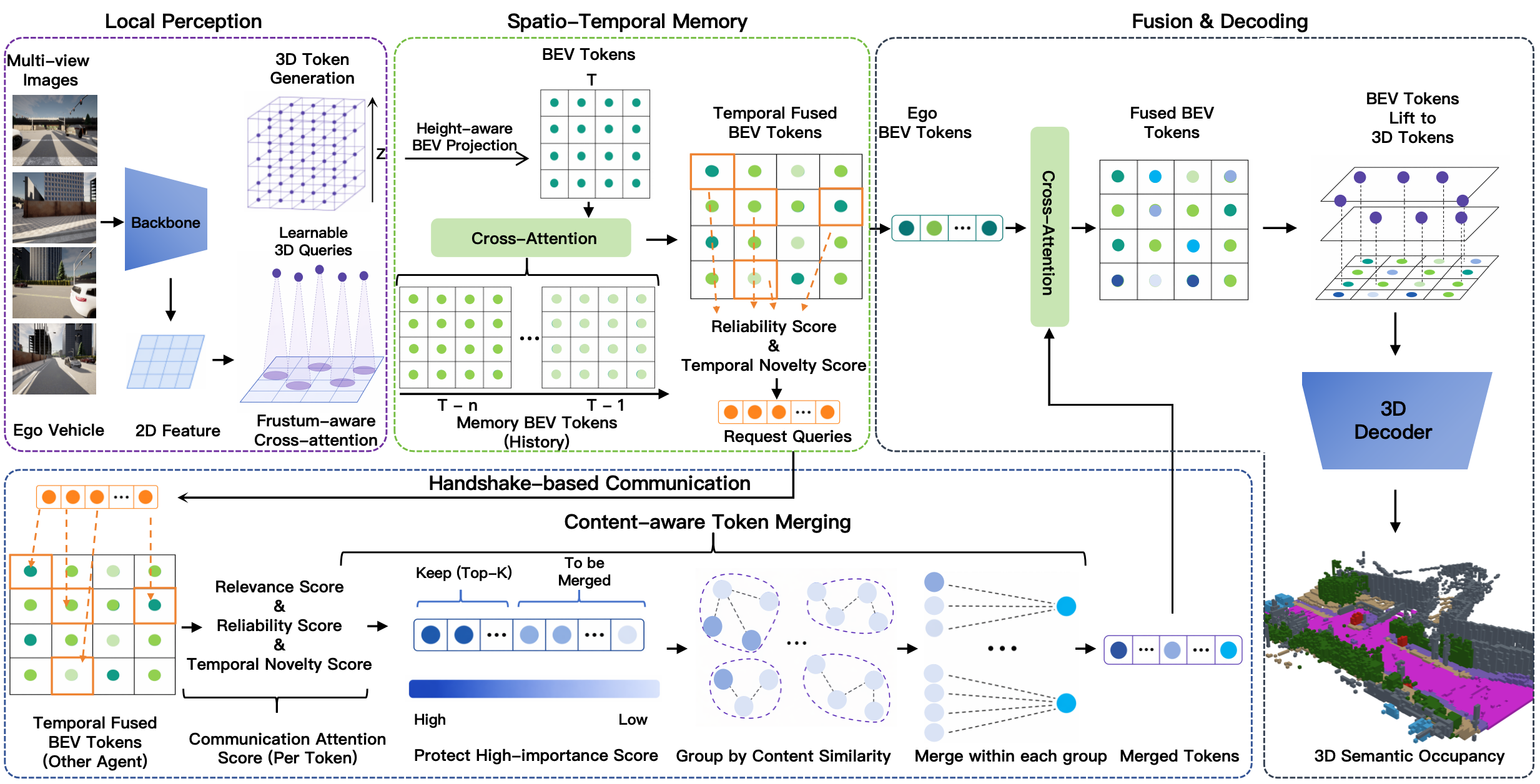
该框架使用 BEV tokens 作为局部感知、时间记忆、智能体通信和协同融合的统一载体。多视角图像首先被 lift 成 3D tokens,再投影为 BEV tokens。时空记忆聚合历史 BEV tokens,ego 车辆生成 receiver-side requests,邻近智能体计算 communication attention scores,并使用 content-aware token merging 在传输前压缩冗余信息。
项目动机
单车感知受遮挡和视野范围限制。协同感知可以利用邻近智能体的观测补全缺失区域,但 dense feature sharing 昂贵且冗余。
本项目关注:
- 如何让智能体通信紧凑的三维场景表示,而不是 dense feature maps?
- ego agent 如何只请求对自身任务有用的信息?
- sender 端如何压缩冗余 tokens,同时保留有用占用证据?
- 如何提升协同语义占用预测中的准确率-通信开销权衡?
这与真实部署密切相关。车联网协同系统不能假设无限带宽,多智能体感知系统必须判断哪些信息值得传输。因此,一个实用的协同感知模型应该同时具备准确性、带宽感知能力和对局部观测缺失的鲁棒性。
问题形式化
给定 ego agent (i) 和邻近智能体集合 (\mathcal{N}_i),目标是预测 ego 视角下的语义占用体:
[ \hat{O}i = f\theta(X_i, {M_{j \rightarrow i}}_{j \in \mathcal{N}_i}) ]
其中:
- (X_i) 是 ego observation;
- (M_{j \rightarrow i}) 是邻居 (j) 发送给 ego (i) 的 message;
- (\hat{O}_i) 是预测的 semantic occupancy grid。
通信预算约束为:
[ \sum_{j \in \mathcal{N}i} \mathrm{Cost}(M{j \rightarrow i}) \leq B ]
项目目标是在该通信预算下最大化占用预测质量。实际实现中,这意味着传输紧凑 token set,而不是 dense intermediate feature maps。
主要贡献
项目提出了一个 token-based collaborative occupancy framework,包含四个关键组件:
- Tokenized 3D/BEV scene representation:用于紧凑 occupancy-oriented communication。
- Spatio-temporal memory:复用历史场景信息,降低单帧不确定性。
- Receiver-driven handshake communication:从 ego 不确定或弱支持区域出发请求信息。
- Content-aware token merging:压缩冗余 sender tokens,同时保留 request-relevant evidence。
核心方法
- 使用 BEV tokens 作为局部感知、时空记忆、智能体通信和协同融合的统一载体。
- 通过时空记忆聚合历史 BEV 表示,提高当前帧占用预测的稳定性。
- 由 ego 端根据不可靠区域生成通信请求,使邻近智能体发送更相关的信息。
- 在 sender 端进行内容感知 token 合并,保留高价值 tokens,同时压缩冗余 tokens。
Tokenized 3D Scene Representation
每个智能体从多视角图像中提取特征,通过 learnable queries lift 成稀疏 3D tokens,再通过 height-aware projection 投影到 BEV tokens。这些 BEV tokens 同时用于感知和通信。
相比 dense feature maps,BEV tokens 更灵活:可以被排序、选择、合并、存入记忆,或通过 attention 融合。因此 token 表示适合带宽受限的协同感知。
Spatio-Temporal Memory
每个智能体维护短期时空记忆。历史 BEV tokens 会根据运动对齐到当前帧,再通过 cross-attention 与当前 BEV tokens 融合,得到时间增强的场景表示。
该模块对当前帧被遮挡或观测不足的区域尤其有帮助。模型不只依赖当前图像,也可以复用历史证据。
Handshake-Based Communication
ego 车辆不是被动接收所有邻居的 dense messages,而是从自身不可靠和时间支持不足区域生成 request queries。邻近智能体再计算 receiver-conditioned communication attention scores,识别哪些 tokens 对 ego 最有帮助。
这种 handshake 机制将通信模式从:
sender broadcasts what it has
改为:
receiver requests what it needs
这很重要,因为 ego 车辆最清楚自己的 occupancy prediction 中哪些区域不确定。
Content-Aware Token Merging
sender 端保留高重要性、与 request 相关的 tokens,并将低优先级冗余 tokens 合并为紧凑代表。合并过程结合 feature similarity 和 spatial proximity,并使用 attention-weighted averaging。
这个过程可以理解为将大 token set (\mathcal{T}) 压缩为更小的 message set (\mathcal{M}):
[ \mathcal{T} \rightarrow \mathcal{M}, \quad |\mathcal{M}| \ll |\mathcal{T}| ]
目标是保留能改善占用预测的 tokens,同时合并相似或冗余的信息。
系统流程
整体 pipeline 为:
多视角图像 -> 3D token lifting -> BEV token projection -> spatio-temporal memory -> receiver-driven request generation -> sender-side token scoring -> content-aware token merging -> collaborative fusion -> 3D occupancy decoding
在该设计中,tokens 是场景编码、时间记忆、通信和融合的统一表示。
实验结果
项目在 Semantic-OPV2V 上进行实验。该 benchmark 基于 OPV2V,面向协同语义占用预测,包含同步多视角 RGB 图像和 connected vehicles 之间的协同感知。
主要设置:
| Setting | Value |
|---|---|
| Dataset | Semantic-OPV2V |
| Occupancy grid | 100 × 100 × 8 |
| Spatial range | 40 m × 40 m × 3.2 m |
| Cameras per agent | 4 RGB views |
| BEV tokens | 100 × 100 |
| Learnable 3D queries | 4320 |
| STM length | 3 frames |
| Max neighboring senders | 6 |
| Transmitted response dimension | 128 |
| Default transmitted tokens / sender | 1000 |
相比 dense feature transmission,token communication 显著降低通信开销,并保持较强的占用预测性能。
| Method | mIoU ↑ | Communication Cost ↓ |
|---|---|---|
| CoHFF | 34.16 | 4.69 MB |
| VOGS-CP | 37.44 | 6.42 MB |
| Ours | 42.85 | 1.48 MB |
该方法在完整协同设置下达到 42.85% mIoU,同时每个 receiver 每帧只需要 1.48 MB feature payload。重要的是,它不是简单用精度换通信,而是在显著降低通信的同时提升了 mIoU,说明 task-aware token selection 和 merging 可以减少冗余通信并增强有用互补信息。
类别级占用结果
| Metric / Class | CoHFF | VOGS-CP | Ours |
|---|---|---|---|
| IoU ↑ | 50.46 | 72.87 | 74.08 |
| mIoU ↑ | 34.16 | 37.44 | 42.85 |
| Building | 25.72 | 9.61 | 20.73 |
| Fence | 27.83 | 29.20 | 36.61 |
| Terrain | 48.30 | 74.51 | 79.83 |
| Pole | 42.74 | 12.19 | 25.47 |
| Road | 61.77 | 83.05 | 82.24 |
| Sidewalk | 39.62 | 78.22 | 72.45 |
| Vegetation | 20.59 | 20.43 | 26.18 |
| Vehicles | 63.28 | 60.49 | 69.73 |
| Wall | 58.27 | 36.45 | 51.10 |
| Guard rail | 1.94 | 32.50 | 27.32 |
| Traffic signs | 16.33 | 8.26 | 18.03 |
| Bridge | 3.53 | 4.35 | 4.51 |
提升主要出现在受互补视角影响较大的类别,例如 fence、terrain、vegetation、vehicles、traffic signs 和 bridge。
消融实验
表示能力和时间建模
增加 3D query density 可以提升空间表示能力,而 spatio-temporal memory 通过聚合历史观测提升鲁棒性。
| 3D Query Density | #Queries | STM Frames | mIoU ↑ |
|---|---|---|---|
| 1× | 1440 | 3 | 36.62 |
| 2× | 2880 | 3 | 38.06 |
| 3× | 4320 | 3 | 42.85 |
| 3× | 4320 | 0 | 39.72 |
| 3× | 4320 | 1 | 41.47 |
| 3× | 4320 | 2 | 42.63 |
| 3× | 4320 | 3 | 42.85 |
通信压缩
Content-aware token merging 在保持强感知性能的同时降低通信成本。
| Setting | #Tokens / Sender | Communication Cost ↓ | mIoU ↑ |
|---|---|---|---|
| Dense communication | 10000 | 14.82 MB | 42.38 |
| Request-guided, no merge | 10000 | 14.82 MB | 42.65 |
| CTM, 50% tokens | 5000 | 7.41 MB | 43.47 |
| CTM, 30% tokens | 3000 | 4.44 MB | 42.91 |
| CTM, 10% tokens | 1000 | 1.48 MB | 42.85 |
10% token 设置将 feature payload 从 14.82 MB 降到 1.48 MB,同时保持有竞争力的 mIoU。50% token 设置取得最高 mIoU,说明适度 token merging 也可能移除冗余或噪声邻居信息。
实验分析
实验结果说明:
- 并非所有协同特征都同样有用,很多传输特征对 receiver 来说是冗余的。
- receiver-side uncertainty 是决定通信内容的重要信号。
- 时间记忆和通信是互补的:memory 稳定本地感知,communication 补充其他视角的缺失区域。
- token merging 不只是压缩,也可以在合并冗余邻居信息时起到一定 denoising 作用。
这些观察进一步推动了我对 communication-efficient multi-agent perception 和 token-based 3D scene representation 的研究兴趣。
可视化结果
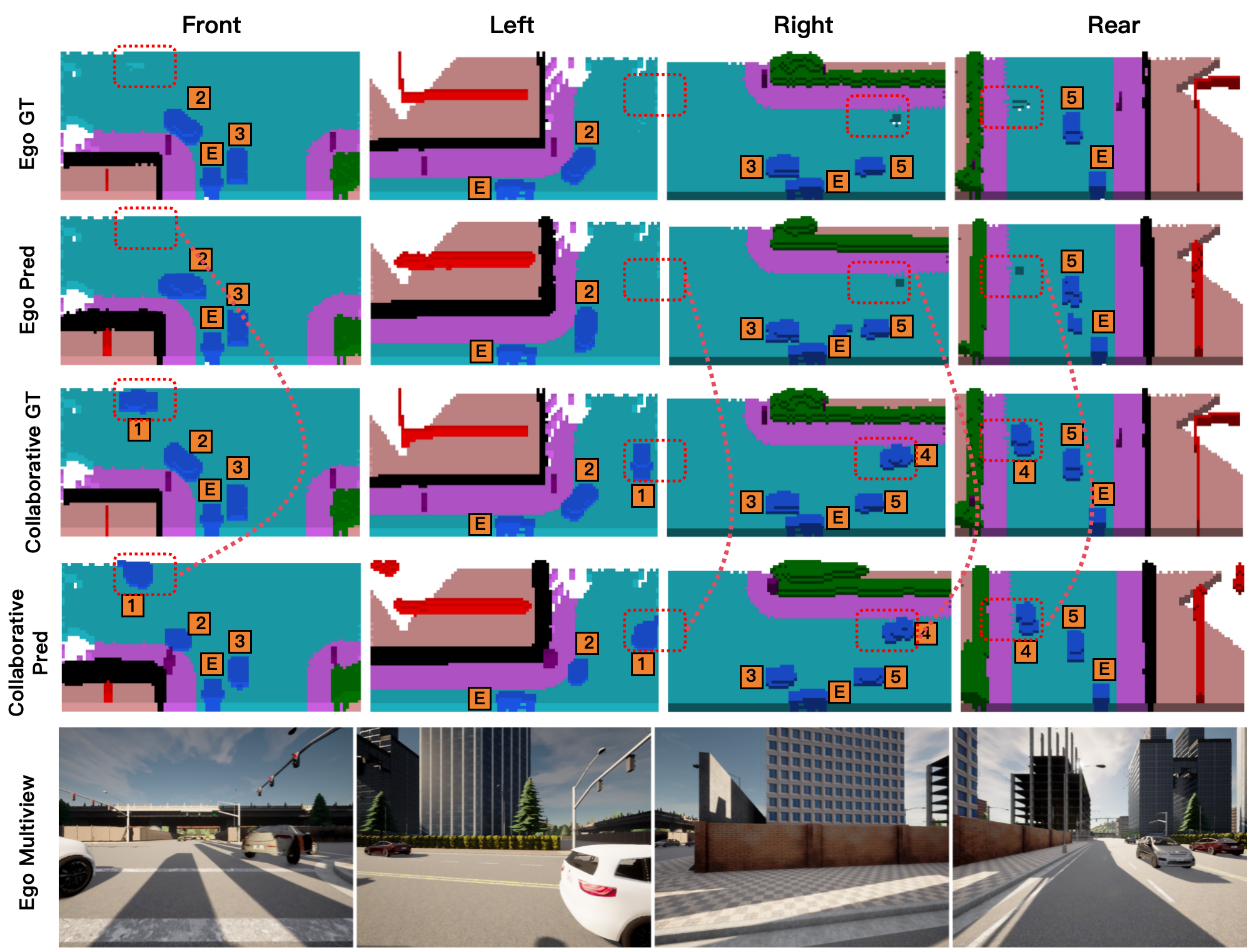
可视化结果表明,协同感知相比 ego-only perception 能生成更完整的语义占用预测,尤其是在车辆和 ego 可靠视野之外的区域。恢复出的区域说明紧凑 token communication 可以在保持较小传输开销的同时补充本地感知。
研究意义
该工作展示了 token 化 BEV 表示在协同占用预测中的潜力,为通信受限的多智能体三维感知系统提供了一种高效设计思路。
关键收获
- Tokenized BEV representations 可以作为协同占用预测的紧凑通信载体。
- Spatio-temporal memory 通过聚合历史 BEV tokens 改善场景表示。
- Receiver-driven communication 让智能体交换 task-relevant information,而不是 broadcast dense features。
- Content-aware token merging 可以压缩 sender 端冗余 tokens,同时保留高重要性信息。
- 该框架在 Semantic-OPV2V 上取得了较好的 accuracy-communication trade-off。
- 该项目进一步强化了我在协同三维感知、高效 token 通信和 occupancy-based scene understanding 方向上的研究定位。
状态
已投稿 NeurIPS 2026。更多细节将在 review 过程之后公开。